Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional...
18 KB (2,281 words) - 22:38, 27 February 2024
well matched to its own cluster and poorly matched to neighboring clusters. If most objects have a high value, then the clustering configuration is appropriate...
13 KB (2,188 words) - 08:30, 1 July 2024

to Cluster analysis. Automatic clustering algorithms Balanced clustering Clustering high-dimensional data Conceptual clustering Consensus clustering Constrained...
69 KB (8,834 words) - 01:54, 13 July 2024
Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the...
22 KB (2,349 words) - 14:13, 12 July 2024
Clustering is the problem of partitioning data points into groups based on their similarity. Correlation clustering provides a method for clustering a...
14 KB (1,969 words) - 13:43, 26 April 2024
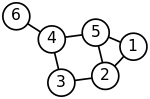
between data points with indices i {\displaystyle i} and j {\displaystyle j} . The general approach to spectral clustering is to use a standard clustering method...
23 KB (2,933 words) - 07:29, 11 December 2023
mixture modeling. They both use cluster centers to model the data; however, k-means clustering tends to find clusters of comparable spatial extent, while...
61 KB (7,688 words) - 21:51, 19 July 2024
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional...
32 KB (4,129 words) - 19:10, 13 May 2024
issue from the process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and...
20 KB (2,750 words) - 07:12, 3 May 2024
In statistical theory, the field of high-dimensional statistics studies data whose dimension is larger (relative to the number of datapoints) than typically...
20 KB (2,560 words) - 23:59, 6 January 2024