
 French
French Deutsch
DeutschSimple Linux Utility for Resource Management , la enciclopedia libre
Slurm (Simple Linux Utility for Resources Management), es un sistema de gestión de tareas y de clústeres (nodos o servidores de cómputo). Slurm como sistema de gestión tiene tres tareas claves:
- Asignar a los usuarios acceso exclusivo o no exclusivo a nodos de cómputo durante un tiempo determinado para que puedan ejecutar sus tareas.
- Proporciona un framework que permite iniciar, ejecutar y supervisar el trabajo.
- Se encarga de arbitrar la disputa de recursos, administrando una cola de tareas pendientes.
En SLURM, debemos de diferenciar dos tipos de roles (que se corresponden con los distintos tipos de usuarios del sistema), que son los “usuarios” y los “administradores”. Ambos interactúan con SLURM mediante un conjunto de comando simples, pero sus propósitos son totalmente contrapuestos:
- Usuarios: Envían trabajos para que se ejecuten, y esperan a que finalice lo más rápido posible y de manera correcta, sin importarles si el trabajo se ha realizado en uno, dos o tres nodos de cómputo.
- Administradores: Debe encontrar la manera de ejecutar trabajos paralelos en nodos paralelos, y lo que es más importante, deben hacer como si el trabajo se ejecutará en un solo nodo. Las tareas de un administrador son:
- Asignar recursos de un nodo de cómputo: Procesadores, memoria, espacio en disco…etc.
- Lanzar y administrar trabajos.
Para poder realizar todas estas tareas de una forma adecuada el administrador debe de conocer de forma concienzuda el hardware con el que se está trabajando.
Características
[editar]- Código abierto.
- Tolerante de fallos.
- Seguro.
- Altamente escalable.
- Altamente configurable: dispone de una gran cantidad de plugins fácilmente usables.
- Es el gestor de colas instalado en muchos de los súper computadores del TOP500.
- Relativamente autónomo.
- Amigable para el administrador.
Arquitectura
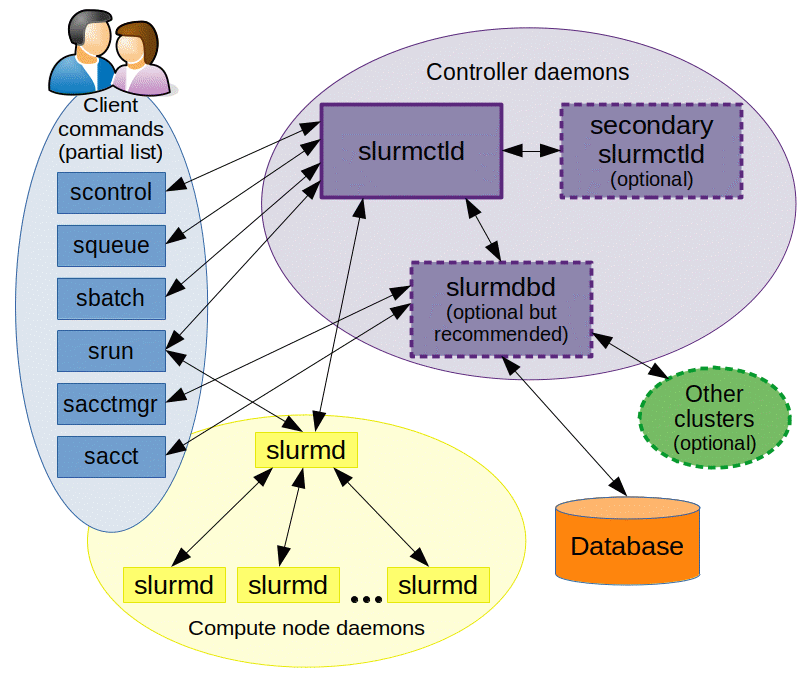
[editar]Mirando la ilustración 1, tenemos que SLURM consiste en un demonio central(slurmctdl) que se ejecuta en un nodo de administración, y se encarga de monitorizar los recursos y el trabajo. Puede existir otro demonio exactamente igual, que será un demonio de respaldo para asumir esa responsabilidad ante posibles fallos.
{kind=link}
En cada nodo de cómputo se ejecuta un demonio(slurmd), cuyo cometido es: esperar trabajos, ejecutar esos trabajos, devolver el resultado de ejecución de esos trabajos y esperar más trabajos. Estos demonios proporcionan comunicaciones jerárquicas tolerantes de fallos.
Existe otro demonio (slurmdbd), que es opcional y que puede usarse para registrar la información relativa a la contabilidad de varios clústeres que estén administrados por SLURM en una única base de datos.
Como ya dijimos anteriormente los usuarios interactúan con SLURM mediante un conjunto de comandos simples, los cuales son:
| Comandos | Descripción |
|---|---|
| srun | Envía un trabajo para su ejecución |
| scancel | Finaliza trabajos que se encuentren en ejecución o pendientes |
| sinfo | Muestra información sobre el estado de los nodos de cómputo |
| squeue | Informa sobre el estado de los trabajos en ejecución en orden de prioridad y luego de los trabajos pendientes también en orden de prioridad |
| sacct | Da información acerca de trabajos completados o que se encuentren activos. |
| smap | Muestra información del estado de los trabajos, particiones y nodos de cómputo, pero muestra la información gráficamente para reflejar la topología de la red |
| sview | Interfaz gráfica para obtener información acerca del estado de los trabajos, particiones y nodos de cómputo |
| salloc | Asigna recursos para un trabajo en tiempo real |
| sattach | Añade una entrada o salida estándar a un trabajo |
| sbatch | Envía un script para su posterior ejecución |
| sbcast | Se utiliza para mandar un archivo a los nodos de cómputo asignados a un trabajo |
| sacctmgr | Herramienta para gestionar la base de datos |
| scontrol | Herramienta administrativa que se utiliza para ver o modificar el estado de SLURM.Muchos comandos control sólo podrán ser ejecutados como root |
| strigger | Nos permite ver, obtener o establecer eventos de activación |
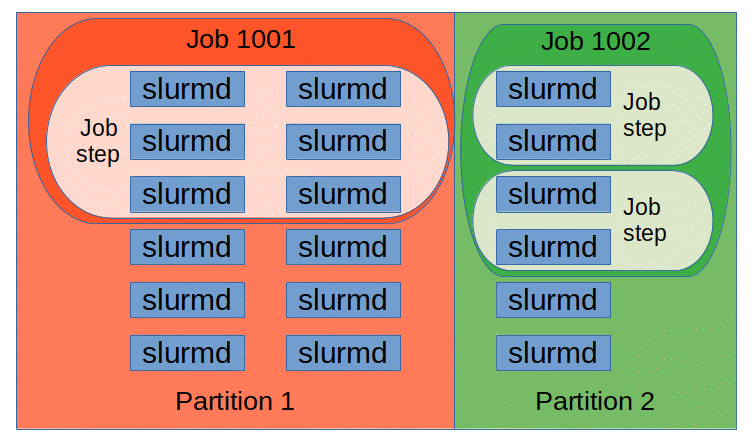
Otro concepto que utiliza SLURM en cuanto a la arquitectura es el de las particiones( ilustración 2). Una partición es una agrupación de nodos que tienen una “conexión fuerte entre ellos”, es decir, que tienen alguna especie de característica en común, por ejemplo: mismo conjunto de funciones hardware o software.
{kind=link}
Como norma, cada nodo debe de estar incluido en al menos una partición, y nada limita que un nodo pueda estar incluido en varias particiones.
¿Cómo funciona?
[editar]- Srun manda una solicitud a slurmctld para iniciar un trabajo, que requiere que se reserven ciertos recursos.
- Slurmctld le responde con el identificador del trabajo, la lista de los recursos reservados y la credencial del trabajo.
- Srun abre los sockets de E/S.
- Srun envía la credencial del trabajo, junto con la información de la tarea a slurmd.
- Slurmd reenvía la petición según sea necesario (en función de los nodos que tengamos reservados).
- Slurmd crea hilos (slurmstepd) mediante forks/execs.
- Slurmstepd conecta con los sockets de E/S de srun e inicia tareas.
- Cuando el trabajo termine slurmstepd notifica a srun.
- Srun notifica a slurmctld la terminación del trabajo.
- Slurmctld verifica la terminación de todos los procesos a través de slurmd y libera recursos para el próximo trabajo.
Ilustración 3:Secuencia de ejecución de un trabajo
Estados de un trabajo
[editar]Una vez visto cómo se ejecuta un trabajo, es interesante ver los estados por los que puede pasar cada uno de ellos.
- Pending: Trabajo en cola.
- Running: Recursos asignados y trabajo en ejecución.
- Suspended: Recursos asignados y trabajo suspendido.
- Completing:
- Cancelled: Trabajo cancelado por el usuario.
- Completed: Trabajo finalizado correctamente.
- Failed: Ejecución finalizada incorrectamente.
- NodeFail: Terminado por fallo en el nodo.
- TimeOut: Terminado por alcanzar el TimeOut.

Prioridad de los trabajos
[editar]De manera predeterminada SLURM utiliza una política FIFO (First In First Out), para gestionar la prioridad de los trabajos.
Si se quiere modificar esta política para gestionar la prioridad de los trabajos, se debe de modificar el parámetro “PriorityType” en el fichero de configuración “slurm.conf”, que por defecto su valor es “priority/basic”, que es lo que permite la programación FIFO.
Multi-factor Job Priority:
En SLURM existe una política muy versátil para ordenar la cola de trabajos en espera, esta es “Multi-factor Job Priority”, y para usarla debemos de modificar el parámetro “PriorityType” en el archivo “slurm.conf” de la siguiente manera: “PriorityType=priority/multifactor”. Hay seis factores en esta política que influyen en la prioridad del trabajo:
- Age: tiempo que un trabajo lleva esperando en la cola. En general cuanto más tiempo lleve esperando mayor prioridad.
- Fair-share: diferencia entre los recursos asignados y los ya consumidos
- Job size: cantidad de nodos o CPU que el trabajo ha solicitado. Este factor se puede configurar para favorecer o bien a los trabajos más grandes o a los más pequeños, para ello en el parámetro PriorityFavorSmall de slurm.conf:
- PriorityFavorSmall = NO, prioriza a los trabajos grandes.
- PriorityFavorSmall = YES, prioriza a los trabajos pequeños.
- Partition: A cada partición se le puede asignar una prioridad. Cuanto mayor sea, mayor será la prioridad de los trabajos que se ejecuten en esa partición.
- QOS (Calidad de servicio): Asociado a la calidad de servicio. Cuanto mayor sea, mayor será la prioridad del trabajo.
- TRES (Recursos rastreables): número de recursos TRES solicitados/asignados en una partición dada. Cuanto mayor número de solicitudes/asignaciones, más prioridad.
La prioridad de los trabajos será la suma ponderada de todos los factores que se le hayan indicado en el archivo “slurm.conf”. Además, podemos asignar un peso a cada uno de los factores para dar más prioridad a unos factores sobre otros.
¿Cómo se regula la exclusión mutua a recursos?
[editar]La programación de los recursos va a depender del tipo de trabajo que se va mandar a ejecución o del complemento de programación que se vaya a elegir.
Trabajos interactivos:
SLURM va despachando los trabajos en función de su prioridad, esto depende totalmente de la política de prioridad que se vaya a utilizar.
Cuando llega una petición de ejecución de un trabajo, SLURM intenta asignarle los recursos que necesita, si es posible le asigna los recursos y comienza la ejecución, si no, se quedará esperando en la petición de inicio de trabajo hasta que los recursos que necesite estén disponibles.
Este método hace que la utilización del sistema y su capacidad de respuesta sea baja. Para ello se puede utilizar el complemento de programación Backfill Scheduling, que viene activado por defecto. Esto hará que se puedan iniciar trabajos de menor prioridad si al hacerlo no se retrasa la hora de inicio de ningún trabajo de mayor prioridad.
Reservas:
Por otra parte, debemos de destacar que SLURM tiene la capacidad de reservar recursos. Los recursos que se pueden reservar incluyen núcleos, nodos, búferes de ráfaga…etc. Una reserva identificará los recursos que están reservados y el periodo de tiempo en el que la reserva estará disponible. En la respuesta de creación de una reserva se incluye el nombre de la misma, que es generado de forma automática por SLURM. Para poder utilizar una reserva, en la solicitud de envío de trabajo se debe de especificar el nombre de la reserva. Por defecto cuando llegue la hora de finalización de una reserva, si el trabajo asociado a la misma no ha terminado este se cancelará. A medida que se acerca la hora de inicio de una reserva, solo se iniciarán los trabajos que se puedan completar antes de que se alcance dicha hora.
El uso de una reserva mejora la prioridad de un trabajo, es decir, cualquier trabajo con una reserva asociada se considera antes para la programación de recursos que cualquier otro trabajo no asociado a una reserva.
Por defecto las reservas no pueden solaparse. Es decir, no pueden existir a la vez dos reservas que incluyan el mismo nodo. Si en una reserva no se especifican los nodos de forma explícita, es SLURM quien se encargará de seleccionarlos de manera que se evite esa superposición y poder garantizar que los nodos estarán disponibles cuando comience la reserva.
Las reservas pueden ser creadas, actualizadas o destruidas solo por el usuario root.
Programación de pandillas:
SLURM permite la programación en grupo, es decir, en la que dos o más trabajos se asignan a los mismos recursos. En este caso, los trabajos se suspenden de manera alternativa para que ambos puedan acceder de manera exclusiva a los recursos durante un período de tiempo previamente configurado (Scheduler Timeslice).
Este tipo de programación mejora la capacidad de respuesta y la utilización del sistema al permitir que más trabajos puedan ejecutarse antes. Los trabajos de ejecución más corta ya no tienen que esperar en una cola detrás de los trabajos más largos, ya que mediante esta ejecución de manera alternativa se les permitirá empezar y terminar antes.
Referencias
[editar]- Documentación oficial de SLURM
- Morris Jette and Mark Grondona SLURM: Simple Linux Utility for Resource
- SLURM Primer (enlace roto disponible en Internet Archive; véase el historial, la primera versión y la última). Northeastern University Research Computing: Nilay K Roy, MS Computer Science, Ph.D Computational Physics
| Control de autoridades |
|
|---|
 Datos: Q3459703
Datos: Q3459703