
 French
French Deutsch
Deutsch字体



漢字 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 書体 | ||||||||||||||||||||
| ||||||||||||||||||||
| 字体 | ||||||||||||||||||||
| ||||||||||||||||||||
| 漢字文化圏 | ||||||||||||||||||||
| 中・日・朝・越・台・琉・新 | ||||||||||||||||||||
| 派生文字 | ||||||||||||||||||||
| 国字 方言字 則天文字 | ||||||||||||||||||||
| 仮名 古壮字 字喃 女書 | ||||||||||||||||||||
| 契丹文字 女真文字 西夏文字 | ||||||||||||||||||||
| →字音 | ||||||||||||||||||||
字体(じたい)とは、図形を一定の文字体系の一字と視覚的に認識する概念、即ち文字の骨格となる「抽象的な」概念のことである。
なお文字コードの策定に当たっては、文字表記体系上において必要な句読点や括弧類、スペースなど意味や音を持たない図形記号の抽象化を含めたグリフ (glyph) という概念も用いられる。
概要
[編集]文字は、言語と直接結び付いて意味を表すものであり、その結び付いた意味によって字種に分類される。そして異なる字種は、原則としてそれぞれ異なる字体を有する。例として図1は「かたな」という意味を持つ字(刀)であり、図2は「やいば」という意味を持つ字(刃)である。このとき図2は図1と比較して一画多い、異なる字体を有している。
しかし、異なる字種が同一の字体を有する場合も稀にある。次項で例を示すが、これらは「同形異字」と呼ばれ、視覚的にはまったく区別することができない。さらに、ひとつの字種に複数の字体が併存していることがある。それら複数の字体はそれぞれ異なる字源から成立している場合もあるし、同じ字源から発生しながらその表現が歴史的・地理的に変化していった結果が固定されている場合もある。例として図2と図3を比較すると中央の筆画の交差に差異が見られるが、これらはともに「ジン」という発音と「やいば」という意味を持つ字である。このように字義、字音が等しい同一の字種でありながら、互いに異なる字体を有する文字を異体字と呼ぶ。異体字のなかで、規範として選ばれている字体を正字体と呼ぶ。異体字と正字体については、それぞれ次節で詳しく述べる。
字体と似た概念に字形(じけい)があるが、これは個別具体の文字の形の総称であり、文字の視覚的な差異はすべて字形の違いとして捉えられる。これまで例として挙げてきた図1・図2・図3についても、字形の違いとして包括することができる。本来、字体は抽象的な概念であるから何らかの書体によって表現されている字形はあくまで参考のためのものに過ぎないと考えられる。しかし字形は常に書体の変遷に応じて大きく変化しているため、あらゆる書体・字形の差を抽象しうる字体というものを想定するのは難しい。
文字コードにおいてその文字集合が包摂規準に従う場合などを除くと、これら字種・字体・字形の弁別は文字体系を共有するもの同士が何らかの合意に達することで行なわれる。すなわち先に挙げた図2と図3の例についてもこれらを字形の違いに留まるものと捉えるか、それとも異なる字体として認めるかということは一意に決まるわけではない。図2と図3は字形が相違するだけで、異体字ではないと考えることもできる。
同形異字
[編集]同形異字とは前文で記したように、同じ形で違う字ということである。
- 例1)芸 ※藝の略字、
芸 ()と芸 () - 例2)灯 ※燈の略字、
灯 ()と灯 ()
正字体
[編集]正字体とはある文字において、最も規範的とされる字体を言う。特にいくつもの字体を有する漢字で問題になり、その選択のしかたによっていくつかの正字の体系が言われる。
正字として重要なのはその典拠とそれを正字とする判断であり、四書では小篆や隷書で示したものが正統の証でもあった。清代の『康熙字典』(1716年)以後は、その字体が規範として尊重された。
中国(清代まで)
[編集]康熙字典以前
[編集]説文解字の親字として示されている小篆は、正字の規範として尊重されてきた。干禄字書は説文解字や経書に示された小篆に基づき、科挙受験者のために楷書の正字体を示した字書である。このような字様書として五経文字、九経字様が引き続き作られた。
康熙字典体
[編集]『康熙字典』は広く流布されたため、そこに示された明朝体の字形を伝統的な楷書の字体に基づいた明朝体の字形と区別して康熙字典体という。ただし『康熙字典』では皇帝の名(玄燁)の「玄」を![]() 」という字形が見られるなど、正字体として用いるには適当でない点があった。そのような実用に適さない部分を変更したものが現在通用している康熙字典体であり、そうした現在でも通用している康熙字典体を端的に明示する際にはこれをいわゆる康熙字典体と呼んで区別することもある。
」という字形が見られるなど、正字体として用いるには適当でない点があった。そのような実用に適さない部分を変更したものが現在通用している康熙字典体であり、そうした現在でも通用している康熙字典体を端的に明示する際にはこれをいわゆる康熙字典体と呼んで区別することもある。
中華圏
[編集]簡体字
[編集]1950年代に中国で新たに制定された中国語の正字体系が簡体字(あるいは簡化字)である。それまで非公認であった俗字(略字)を正式な字体としている。中国およびシンガポール、マレーシアで使用されている。第二次漢字簡化方案などのように、試用されたが正式に実施されず、廃案となったものも存在する。
繁体字
[編集]台湾、香港、マカオなどで使用される、簡略化されていない字体が繁体字である。繁体字という呼び方は、中国大陸での呼び方であり、台湾の公的文書では標準字と呼んでいる[1]。他に正体字などとも呼ばれる。地域によって異体字の扱いが異なったり、字体に細かい異同が見られる。中国では2013年の『通用規範漢字表』[2]に附属の『規範字と繁体字、異体字対照表』(ここでいう規範字は簡体字を指す)で字体を示しているが、台湾、香港の字体と異なるものが多い(詳しくは『通用規範漢字表』を参照)。
繁体字は、康熙字典体と同じではない。喻(康熙字典体喩)、留(康熙字典体畱)、麵(康熙字典体麪)、真(康熙字典体眞)、值(康熙字典体値)、并(康熙字典体幷)、啟(康熙字典体啓)、即(康熙字典体卽)、痺(康熙字典体痹)、為(康熙字典体爲)、青(康熙字典体靑)などは、康熙字典体とは異なる字体が標準または一般的になっている。食偏(飠)、しんにょう、示偏(礻)も、康熙字典体とは異なるものを使用する。
新字形
[編集]1960年代の中国で、康熙字典体に代わる標準印刷字体として制定されたものが新字形である。より筆記体に近い字体が採用され、減画や異体字の整理がなされている。簡体字と混同されることがあるが、簡体字だけでなく繁体字も含めた字体体系である。なお、中国の漢字学においては字形と字体を一般に区別しない。
日本
[編集]韓国
[編集]大韓民国(韓国)で使用されている漢字(ハンチャ)は、特別な簡略化を受けていない。おおむね上記の繁体字に一致する。
仔細に見れば、韓国で学校教育に使われる漢文教育用基礎漢字の字体は、康熙字典体とも台湾・香港の繁体字とも異なる。例示すれば、留(康熙字典体畱)、鬪(康熙字典体鬬)、告(康熙字典体吿)、顔(康熙字典体・繁体字顏)、産(康熙字典体・繁体字產)、衆(康熙字典体・繁体字眾)、衛(康熙字典体衞)などである。草冠は、康熙字典体・繁体字が4画(艹)に作るのに対し、韓国の教育用漢字は3画(艹)に作る。
なお、朝鮮民主主義人民共和国(北朝鮮)では漢字を廃止している。
異体字
[編集]同一の文字観念を有する複数の字体であり、実際の使用される文章においては異体字は相互に置換が可能である。正字体に対して異なる字体を異体字というのと同様に正字体も別の字体にとっては異体字であり、その関係は相互的である。漢字はその字形のゆれが大きく、また書体の変遷により異なる字体を持つことが多い。複数の字体が同一の文字について許容されることもあるが結果として別の意味が割り当てられ、その用法が区別されるようになるともはや別字となる(「吊」と「弔」、「著」と「着」、「句」と「勾」、「笑」と「咲」など)。「叶」は本来「協」と同字の別体であったが、意味が分化し日本では「かなう」、中国の簡体字では「葉」の意になるなど国ごとの分化さえ見られる。日本では壬申戸籍(1872年)の作成の際にあった誤字や書き癖が戸籍にある字形を尊重した結果、当用漢字・常用漢字に対しての異体字として認知されるにいたる場合も多い。
古字(古文)は秦の始皇帝による小篆普及以前の大篆(籀文)など、古い字体に基づく字を指す。「一」に対する「弌」、「協」に対する「叶」など。
俗字・通字とは、正字として認められた字体以外で通用されている文字を指す。正字規範の高まりと共に認知されるにいたった。俗字には別の部品を当てるもの、同じ音をもつ部品を当てるもの、画数を減らすもの、別の部品を付け足すもの、異なる発想で会意字を作るものなどがある。「卒」に対する「卆」、「崎」に対する「﨑」(あるいは「嵜」「㟢」(山冠に奇))、「富」に対する「冨」、「場」に対する「塲」、「淵」に対する「渕」(あるいは「渊」)、「哲」に対する「喆」、「高」に対する「髙」、「橋」に対する「槗」「𣘺」、「魚」に対する「𩵋」(「魚」の下の部分が「れんが(灬)」ではなく「大」)、「解」に対する「觧」、「翠」に対する「翆」など(機種依存文字も含まれているため、一部のパソコンや携帯電話からは閲覧出来ない場合がある)。
異体字の例
[編集]異体字は次のような種類に分けられる。
- 同じ構成要素をもつが、その配置が異なるもの(動用字[3])
- 隣 - 鄰
- 和 - 咊
- 飄 - 飃
- 峰 - 峯
- 㟁 - 岸
- 群 - 羣
- 鵝 - 鵞
- 鑑 - 鑒
- 慚 - 慙
- 晰 - 晳
- 稿 - 稾
- 雜 - 襍
- 裏 - 裡
- 松 - 枩
- 島 - 嶋 - 嶌
- 異なる音符を使ったもの
- 棲 - 栖
- 綫 - 線
- 麪 - 麵
- 卻 - 却
- 筍 - 笋
- 窯 - 窰
- 嶋 - 嶹
- 鐵 - 鉄(鉃は別字)
- 異なる意符を用いたもの
- 効 - 效
- 秘 - 祕
- 嘆 - 歎
- 睹 - 覩
- 暖 - 煖
- 器 - 噐
- 収 - 收
- 詠 - 咏
- 唇 - 脣
- 罰 - 罸
- 考 - 攷
- 恥 - 耻
- 埆 - 确
- 翻 - 飜
- 一方が形声で作られ、一方が会意で作られたもの
- 涙 - 泪
- 巌 - 岩
- 渺 - 淼
- 拏 - 拿
- 逃 - 迯
- 葉 - 叶
- 傑 - 杰
- 輭 - 軟
- 会意や形声の仕方が異なり、字体上の共通項もないもの
- 體 - 体
- 同 - 仝
- 村 - 邨
- 略体・書き癖・運筆の連綿などによって生じたもの(竹冠と草冠、「口」と「ム」、「
 」と「
」と「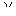 」などは相互置換される例が特に多い)
」などは相互置換される例が特に多い) - 莚 - 筵
- 船 - 舩
- 曾 - 曽
- 鰺 - 鯵
- 龍 - 竜
- 點 - 点
- 蠶 - 蚕
- 晝 - 昼
- 畫 - 画
- 讀 - 読
- 戀 - 恋
- 傳 - 伝
異体字の認定
[編集]一般に字義・字音が同じであり、同じ文脈で交換して使用可能なものを異体字と認定できる。すべての字義において交換可能なものもあるが、一部の字義にのみ通用される異体字もある。
ただし特に中国では字義・字音の歴史的な変化により、認定に難しい問題がある。第1には、古代の字音が同じでないもの。例えば
逆に古代において異体字であったものが後には意味の棲み分けをして異体字関係でなくなったものがある。例えば先秦・漢代の文献で「諭」と「喩」はともに「さとす・たとえる」の意味をもち通用されているが、後には「さとす」は「諭」、「たとえる」には「喩」が使われるようになった。特に意符を異にする異体字間でこのような事例が多い。以前は異体字関係であったものとして、他に脇・脅、弔・吊、著・着、果・菓、棋・碁、咲・笑、茶・荼などがある。
なお異体字関係にある文字がすべて正字・俗字に分けられるわけではない。時代の流行、個人の趣向などにより同様に広く使われてきたものが多い。「椀」や「碗」、「槍」や「鎗」、「鉱」や「砿」など同音同義語であるにもかかわらず、材質という細かなニュアンスの違いなどでも次々に異体字が作られる。これらを一概に整理統一することは非常に困難である。
文字集合と異体字
[編集]JIS X 0208などの文字集合では基本的に情報交換用の文字を示すのが目的であるため、異体字ごとにコードポイントを割り振ったりはしないことが原則である(ただし固有名詞対応の必要性などから、複数の異体字に個別のコードが与えられているケースが多数見られる)。そのため、コンピュータ上で表示される文字はフォントを作る場合にその一例として採用した文字にすぎない。符号上は正しい文字だがフォントの関係上意図していた字体と違う場合も多く、異体字を包摂(一つのコードポイントに異体字を統合)せずに別にできる方法が必要という声もある。例えばいわゆる「髙=はしごだか」と「高=くちだか」では符号区点は一つしかないが、別のコードポイントを与えるべきだとの声もある。
Unicodeでも基本的に事情は同様であるがその一方でさまざまな既存の規格を取り込む際に「原規格分離 (source code separation) の原則」によって異体字に別のコードポイントが与えられたものもあり(「髙=はしごだか」と「高=くちだか」もこれに該当)、さらに混沌としている。
Unicodeでは、漢字の異体字の問題については「異体字タグ (variant tag)」の導入により包括的な解決を企図するとしていた。実際にUnicode 3.2では異体字タグは「異体字セレクタ(異体字選択子、字形選択子、英: Variation Selector)」という名称で16文字分 (U+FE00 - U+FE0F) が、Unicode 4.0では240文字分 (U+E0100 - U+E01EF) が追加された。規格書には「先行する1文字と組み合わせることによって、あらかじめ定義付けされた異なる字体を任意に選択できる」とあり、理屈の上では1文字につき256種類の異体字情報を持つことができるようになった。その後、2006年1月13日に漢字で異体字セレクタを使うための漢字字形データベース (Ideographic Variation Database) への登録手続きが定められ2007年12月14日に最初の異体字コレクションとしてAdobe-Japan1が登録された。なお、異体字セレクタのうち特に漢字に関するものは「IVS (Ideographic Variation Selector)」と呼ばれる。2009年、Windows 7、Mac OS X 10.6 (Snow Leopard) といったOSがIVSに対応、Adobe製品やJustsystem製品などが順次アプリケーションレベルでIVSに対応していった[4]。Microsoft Officeは2013バージョンから正式にIVSに対応している(2007と2010はアドオンで対応)。
IVSなどに対応していない環境で、文字コードに依存せず異体字を切り替えるには以下のような手法が取られている。
- フォント切り替え(裏フォント方式)
- 同じコードポイントに異体字を収録したフォントを複数(異体字の種類分)用意し、それによって字体の切り替えを行う。例えば「日本語・JIS90規格」「日本語・JIS2004規格」「中国語・簡体字」「中国語・繁体字(台湾)」「中国語・繁体字(香港)」「朝鮮語」のフォントにそれぞれ異なるグリフが含まれている組み合わせを挙げる。以下の字のうち背景色をグレーにした文字は他のタイプのフォントだと代用が利かない。
日本語 中国語 朝鮮語 JIS90 JIS2004 簡体字 繁体字 台湾 香港 倦 倦 倦 倦 倦 倦 倦 葛 葛 葛 葛 葛 葛 葛 芒 芒 芒 芒 芒 芒 芒 煎 煎 煎 煎 煎 煎 煎 嘲 嘲 嘲 嘲 嘲 嘲 嘲 曜 曜 曜 曜 曜 曜 曜 龍 龍 龍 龍 龍 龍 龍 寒 寒 寒 寒 寒 寒 寒 返 返 返 返 返 返 返
- CIDフォント、OpenTypeフォントによる字体切り替え
- CIDフォントおよびその後継であるOpenTypeフォントは一つの文字コードに複数のグリフを関連付けさせたテーブルを内蔵しており、Adobe-Japan1文字集合に対応したOS、ウェブブラウザを含むアプリケーションで字体切り替えが可能となっている。
上記の手法はいずれもフォントに依存した異体字切り替えであり、異なった環境同士での情報交換にはフォント埋め込みなどの手段が必要とされる。フォント埋め込みができる文書フォーマットとしては「PDF」などが挙げられる。Adobe-Japan文字集合には未対応だが「Microsoft Word」もフォント埋め込みに対応している。
脚注
[編集]参考文献
[編集]- 野村雅昭・小池清治編『日本語辞典』東京堂出版、1992。
- 内田明「公有フォントを作る」『Linux Japan』2002.2月号、五橋研究所、2002。
- 小川環樹・西田太一郎・赤塚忠編『新字源』角川書店、1968。
- 小形克宏『小形克宏の「文字の海、ビットの舟」――文字コードが私たちに問いかけるもの』インプレス、2000-2004。
- 加藤弘一『図解雑学 文字コード』ナツメ社、2002。
関連項目
[編集]外部リンク
[編集]- 教育部異體字字典
- CHISE IDS 漢字検索 - 漢字の構成部品を検索すれば、その部品を使っている字をリストアップできる。