
 French
French Deutsch
DeutschAnálise exploratória de dados – Wikipédia, a enciclopédia livre
| Estatística |
|---|
 |
Em estatística, a análise exploratória de dados (AED) é uma abordagem à análise de conjuntos de dados de modo a resumir suas características principais, frequentemente com métodos visuais. Um modelo estatístico pode ou não ser usado, mas primariamente a AED tem como objetivo observar o que os dados podem nos dizer além da modelagem formal ou do processo de teste de hipóteses. A análise exploratória de dados foi promovida pelo estatístico norte-americano John Tukey, que incentivava os estatísticos a explorar os dados e possivelmente formular hipóteses que poderiam levar a novas coletas de dados e experimentos. A AED é diferente da análise inicial de dados (AID), que se concentra mais estreitamente em verificar os pressupostos exigidos para ajuste de modelos e teste de hipóteses, além de manusear valores faltantes e fazer transformações de variáveis conforme necessário. A análise exploratória de dados abrange a AID.[1]
A análise exploratória de dados emprega grande variedade de técnicas gráficas e quantitativas, visando maximizar a obtenção de informações ocultas na sua estrutura, descobrir variáveis importantes em suas tendências, detectar comportamentos anômalos do fenômeno, testar se são válidas as hipóteses assumidas, escolher modelos e determinar o número ótimo de variáveis.
Os softwares atualmente disponíveis possibilitam que esta técnica se constitua em uma ferramenta para descobrir quais tendências, relações e padrões podem estar ocultos em uma coleção de dados analisados. Seguindo as diretrizes propostas por Tukey, os investigadores deveriam iniciar sua análise pelo exame dos dados disponíveis e depois decidir qual técnica aplicar para resolver o problema.
Visão geral
[editar | editar código-fonte]Tukey definiu a análise de dados em 1961 como: "[P]rocedimentos para analisar dados, técnicas para interpretar os resultados de tais procedimentos, formas de planejar a reunião dos dados para tornar sua análise mais fácil, mais precisa ou mais exata e toda a maquinaria e os resultados da estatística (matemática) que se aplicam a análise de dados."[2]
A defesa da AED por Tukey encorajou o desenvolvimento de pacotes de estatística computacional, especificamente a S na Bell Labs. A linguagem de programação S inspirou os sistemas S-PLUS e R. Esta família de ambientes de estatística computacional incluiu capacidades de visualização dinâmica altamente melhoradas, que permitiram aos estatísticos identificar valores atípicos, tendências e padrões em dados que mereciam estudos posteriores.[3][4]
A análise exploratória de dados de Tukey estava relacionada com outros dois desenvolvimentos na teoria estatística: a estatística robusta e a estatística não paramétrica, ambas as quais tentavam reduzir a sensibilidade das inferências estatísticas a erros na formulação de modelos estatísticos.[5] Tukey promoveu o uso do resumo dos cinco números de dados números — os dois extremos (máximo e mínimo), a mediana e os quartis — já que a mediana e os quartis, sendo funções da distribuição empírica, são definidos para todas as distribuições, diferentemente da média e do desvio padrão. Além disso, a mediana e os quartis são mais robustos em relação a distribuições oblíquas e de cauda pesada do que os resumos tradicionais (a média e o desvio padrão). Os pacotes S, S-PLUS e R incluem rotinas usando estatísticas de reamostragem, tais como o jackknife de Quenouille e Tukey e o bootstrapping de Efron, que são não paramétricas e robustas (para muitos problemas).[6]
A AED, a estatística robusta, a estatística não paramétrica e o desenvolvimento das linguagens de programação estatística facilitaram o trabalho dos estatísticos em problemas de ciência e engenharia. Tais problemas incluíam a fabricação de semicondutores e a compreensão de redes de comunicação, que interessavam à Bell Labs. Estes desenvolvimentos estatísticos, todos defendidos por Tukey, foram desenhados para complementar a teoria analítica dos testes de hipóteses estatísticas, particularmente a tradição laplaciana de ênfase em famílias exponenciais.[7]
Desenvolvimento
[editar | editar código-fonte]Tukey publicou o livro Exploratory Data Analysis em 1977.[8] Tukey acreditava que se dava ênfase demais em estatística aos testes de hipóteses estatísticas (análise confirmatória de dados) e que se precisava dar mais ênfase ao uso de dados para sugerir hipóteses a se testarem. Em particular, Tukey acreditava que confundir os dois tipos de análises e empregar ambos no mesmo conjunto de dados poderiam levar a viés sistemático devido a questões inerentes aos testes de hipóteses sugeridos pelos dados.[9]
Os objetivos da AED são:
- Sugerir hipóteses sobre as causas dos fenômenos observados;
- Avaliar pressupostos sobre os quais a inferência estatística se baseará;
- Apoiar a seleção de ferramentas e técnicas estatísticas apropriadas;
- Oferecer uma base para coleta posterior de dados por meio de surveys e experimentos.[10]
Muitas técnicas de análise exploratória de dados têm sido adotadas em mineração de dados, assim como em análise de big data.[11] Também têm sido ensinadas a jovens estudantes como uma forma de introdução ao pensamento estatístico.[12][13]
Técnicas
[editar | editar código-fonte]Há várias ferramentas úteis para a análise exploratória de dados, mas a AED é mais caracterizada pela atitude tomada do que por técnicas particulares.[14]
Técnicas gráficas típicas usadas na análise exploratória de dados são:[15][16]
- Diagrama de caixa;
- Histograma;
- Carta de controle multivariada;[17]
- Diagrama de Pareto;
- Carta de sequência;
- Gráfico de dispersão;
- Diagrama de ramos e folhas;
- Coordenadas paralelas;[18]
- Razão de possibilidades;
- Perseguição da projeção;
- Redução de dimensionalidade:
- Escalonamento multidimensional;
- Análise de componentes principais (ACP);
- Análise de componentes principais multilinear;
- Redução de dimensionalidade não linear (RDNL);
- Métodos de projeção como grande volta, volta guiada e volta manual;
- Versões interativas destes diagramas.
Técnicas quantitativas típicas são:
- Polimento da mediana;
- Tri-média;
- Ordenação.
Histórico
[editar | editar código-fonte]Muitas ideias da AED podem ser remontadas a autores anteriores, por exemplo:
- O matemático britânico Francis Galton enfatizava estatísticas de ordem e quantis;
- O estatístico britânico Arthur Lyon Bowley usava precursores do diagrama de ramos e folhas (Bowley, na verdade, usava um resumo de sete números, incluindo os extremos, decis e quartis, ao lado da mediana);[19]
- O estatístico alemão Andrew Ehrenberg articulou uma filosofia de redução de dados.[20]
Exemplo
[editar | editar código-fonte]Descobertas a partir da análise exploratória de dados são frequentemente ortogonais à tarefa de análise primária. Para ilustrar, considere um exemplo em que a tarefa da análise é encontrar as variáveis que melhor preveem a gorjeta que os clientes de uma mesa em um jantar darão ao garçom.[3] As variáveis disponíveis nos dados coletados para esta tarefa são: o montante da gorjeta, o montante da conta, o gênero do pagante, seção de fumantes/não fumantes, a hora do dia, o dia da semana e o tamanho da mesa. A tarefa da análise primária é aproximada ao ajustar um modelo de regressão em que a razão da gorjeta é a variável de resposta. O modelo ajustado é

que diz que, à medida que o tamanho da mesa aumenta em um cliente (levando a uma conta maior), a razão da gorjeta diminuirá em 1%. Entretanto, a exploração dos dados revela outras características interessantes não descritas neste modelo.
-
 Histograma de montantes de gorjeta em que as classes cobrem incrementos de $1. A distribuição de valores é oblíqua à direita e unimodal, como é comum em distribuições de quantidades pequenas, não negativas.
Histograma de montantes de gorjeta em que as classes cobrem incrementos de $1. A distribuição de valores é oblíqua à direita e unimodal, como é comum em distribuições de quantidades pequenas, não negativas. -
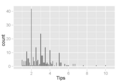 Histograma de montantes de gorjeta em que as classes cobrem incrementos de $0,10. Um fenômeno interessante é visível: picos ocorrem em montantes de dólar inteiro e meio dólar, o que é causado pelo escolha de números redondos para gorjeta pelos clientes. Este comportamento é comum em outros tipos de compras também.
Histograma de montantes de gorjeta em que as classes cobrem incrementos de $0,10. Um fenômeno interessante é visível: picos ocorrem em montantes de dólar inteiro e meio dólar, o que é causado pelo escolha de números redondos para gorjeta pelos clientes. Este comportamento é comum em outros tipos de compras também. -
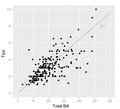 Gráfico de dispersão de gorjetas versus contas. Pontos abaixo da linha correspondem a gorjetas que são menores do que o esperado. Podemos esperar ver uma associação linear positiva, apertada, mas, em vez disso, vemos uma variação que aumenta com o montante da gorjeta. Em particular, há mais pontos muito distantes da linha na direita abaixo do que na esquerda acima, indicando que mais clientes são muito avaros do que muitos generosos.
Gráfico de dispersão de gorjetas versus contas. Pontos abaixo da linha correspondem a gorjetas que são menores do que o esperado. Podemos esperar ver uma associação linear positiva, apertada, mas, em vez disso, vemos uma variação que aumenta com o montante da gorjeta. Em particular, há mais pontos muito distantes da linha na direita abaixo do que na esquerda acima, indicando que mais clientes são muito avaros do que muitos generosos. -
 Gráfico de dispersão de gorjetas versus contas separado por gênero do pagante e seção de fumantes/não fumantes. Mesas com fumantes têm muito mais variabilidade nas gorjetas que dão. Homens tendem a pagar as (poucas) contas mais altas e as mulheres não fumantes tendem a ser muito consistentes ao darem gorjeta (com três exceções notáveis exibidas na amostra).
Gráfico de dispersão de gorjetas versus contas separado por gênero do pagante e seção de fumantes/não fumantes. Mesas com fumantes têm muito mais variabilidade nas gorjetas que dão. Homens tendem a pagar as (poucas) contas mais altas e as mulheres não fumantes tendem a ser muito consistentes ao darem gorjeta (com três exceções notáveis exibidas na amostra).




O que se aprende dos gráficos é diferente do que é ilustrado pelo modelo de regressão, ainda que o experimento não tenha sido desenhado para investigar qualquer destas outras tendências.[21] Os padrões encontrados ao explorar os dados sugerem hipóteses sobre as gorjetas que podem não ter sido antecipadas e que poderiam levar a interessantes experimentos em sequência em que as hipóteses são formalmente expostas e testadas na coleta de novos dados.
Software
[editar | editar código-fonte]Exemplos de software adequados para a AED incluem:[22]
- Cornerstone, um pacote de análise exploratória de dados;
- Data Applied, um ambiente baseado na web abrangente em visualização e mineração de dados;
- GGobi, um software livre para visualização interativa de dados;
- JMP, um pacote de AED do SAS Institute;
- KNIME (Konstanz Information Miner), plataforma em código aberto de exploração de dados baseada em Eclipse;
- Orange, uma suíte de software em código aberto de mineração de dados e aprendizado de máquina;
- Python, uma linguagem de programação em código aberto de mineração de dados e aprendizado de máquina;
- R, uma linguagem de programação em código aberto para computação e gráficos estatísticos, que é, junto com o Python, uma das linguagens mais populares para ciência de dados;
- SOCR, que oferece uma grande quantidade de ferramentas on-line gratuitas;
- TinkerPlots, um software de análise exploratória de dados para alunos do segundo ciclo do ensino fundamental;
- Weka, um pacote em código aberto de mineração de dados que inclui ferramentas de visualização e AED, como a perseguição de projeção.
Ver também
[editar | editar código-fonte]Referências
- ↑ Christopher., Chatfield, (1995). Problem solving : a statistician's guide 2nd ed. London: Chapman & Hall. ISBN 0412606305. OCLC 32881624
- ↑ Tukey, John W. (1962). «The Future of Data Analysis». The Annals of Mathematical Statistics (em inglês). 33 (1): 1–67. ISSN 0003-4851. doi:10.1214/aoms/1177704711
- ↑ a b Dianne., Cook, (2007). Interactive and Dynamic Graphics for Data Analysis : with R and GGobi. New York: Springer Verlag. ISBN 9780387717616. OCLC 154711874
- ↑ W., Young, Forrest; Michael., Friendly, (2006). Visual statistics : seeing data with dynamic interactive graphics. Hoboken, N.J.: Wiley-Interscience. ISBN 9780471681601. OCLC 64689034
- ↑ 1944-, Hoaglin, David C. (David Caster),; 1916-2006., Mosteller, Frederick,; 1915-2000., Tukey, John W. (John Wilder), (1983). Understanding robust and exploratory data analysis. New York: Wiley. ISBN 0471097772. OCLC 8495063
- ↑ L., Martinez, Wendy; 1955-, Solka, Jeffrey L., (2011). Exploratory data analysis with MATLAB 2nd ed. Boca Raton, Fla.: CRC Press. ISBN 9781439812204. OCLC 649802831
- ↑ Fernholz, Luisa T.; Morgenthaler, Stephan (1 de fevereiro de 2000). «A conversation with John W. Tukey and Elizabeth Tukey». Statistical Science (em inglês). 15 (1): 79–94. ISSN 0883-4237. doi:10.1214/ss/1009212675
- ↑ 1915-2000., Tukey, John W. (John Wilder), (1977). Exploratory data analysis. Reading, Mass.: Addison-Wesley Pub. Co. ISBN 9780201076165. OCLC 3058187
- ↑ Natalia., Andrienko, (2006). Exploratory analysis of spatial and temporal data : a systematic approach. Berlin: Springer. ISBN 3540259945. OCLC 209952518
- ↑ Behrens, John (1 de junho de 1997). «Principles and Procedures of Exploratory Data Analysis». Psychological Methods. 2: 131–160. doi:10.1037/1082-989X.2.2.131
- ↑ Macario, Giuseppe (28 de julho de 2015). «Merging exploratory data analysis with operational data analysis». Consultado em 12 de fevereiro de 2018
- ↑ Konold, Clifford. «Statistics Goes to School.». PsycCRITIQUES (em inglês). 44 (1). doi:10.1037/001949
- ↑ Leinhardt, Gaea; Leinhardt, Samuel (1 de janeiro de 1980). «Exploratory Data Analysis: New Tools for the Analysis of Empirical Data». Review of Research in Education. Consultado em 12 de fevereiro de 2018
- ↑ Tukey, John W. (1 de novembro de 1978). «We Need Both Exploratory and Confirmatory». The American Statistician. Consultado em 12 de fevereiro de 2018
- ↑ Martin., Theus, (2009). Interactive graphics for data analysis : principles and examples. Boca Raton: CRC Press. ISBN 9781584885948. OCLC 245023938
- ↑ C., Toit, S. H.; H., Stumpf, R. (1986). Graphical Exploratory Data Analysis. New York, NY: Springer New York. ISBN 9781461293712. OCLC 840279850
- ↑ Michel., Jambu, (1991). Exploratory and multivariate data analysis. Boston: Academic Press. ISBN 0123800900. OCLC 22703744
- ↑ 1936-, Inselberg, Alfred, (2009). Parallel coordinates : visual multidimensional geometry and its applications. Dordrecht: Springer. ISBN 9780387686288. OCLC 656399247
- ↑ Bowley, Sir Arthur Lyon (1915). An Elementary Manual of Statistics (em inglês). [S.l.]: P.S. King & son, Limited
- ↑ C., Ehrenberg, A. S. (1982). A primer in data reduction : an introductory statistics textbook. Chichester [West Sussex]: Wiley. ISBN 9780471101352. OCLC 8451280
- ↑ 1944-, Hoaglin, David C. (David Caster),; 1916-2006., Mosteller, Frederick,; 1915-2000., Tukey, John W. (John Wilder), (1985). Exploring data tables, trends, and shapes. New York: Wiley. ISBN 0471097764. OCLC 11550398
- ↑ 1949-, Velleman, Paul F., (1981). Applications, basics, and computing of exploratory data analysis. Boston, Mass.: Duxbury Press. ISBN 087150409X. OCLC 6304721